|
Lezioni di geometria Franco Ghione |
|
Spazi vettoriali su campi finiti. La teoria degli spazi vettorili considera due operazioni fondamentali tra i vettori dello spazio: la prima è la somma di vettori e la seconda è il prodotto di un vettore per uno scalare. Guardando ora a ritroso e ripercorrendo il camminio fatto, dal concetto di indipendenza lineare, di base, di dimensione, di riduzione di Gauss a quello di applicazione lineare, di nucleo e di immagine, ci accorgiamo del fatto che le sole proprietà degli scalri che abbiamo usato nelle dimostrazioni dei nostri teoremi sono quelle relative alle operazioni elementari dell'aritmetica : somma, prodotto, sottrazione e divisione. Solo in relazione allo studio del prodotto scalare, relativamente alla considerazione del modulo di un vettore, abbiamo avuto la necessità di estrarre delle radici quadrate introducendo operazioni irrazionali nel campo degli scalari. Prescindendo quindi dal prodotto scalare, possiamo sviluppare la teoria degli spazi vettoriali prendendo come scalari un qualunque insieme "numerico" che abbia le stesse caratteristiche dell'aritmetica ordinaria. Tali insiemi, che possono essere anche finiti, si chiamano campi e verranno studiati dettagliatamente nel corso di Algebra. Ora faremo solo un esempio di campo finito, il più semplice possibile: il campo F delle classi resto modulo due. Tale campo ha due soli elementi che indichiamo con i simboli 0 ed 1. F = {0,1} Le operazioni tra questi due elementi si eseguono seguendo le seguenti regole: 0.0=0, 0.1=1.0=0 1.1=1 Dato che abbiamo solo due elementi si vede subito che valgono le proprietà associative commutative e distributive.
Inoltre esiste sempre l'opposto dato che l'opposto di 0 è 0 (la relazione x+0=0 è soddisfatta
per x=0) e l'opposto di 1 è 1 (la relazione x+1=0 è soddisfatta da x=1). Analogamente l'unico elemento non nullo del
campo è 1 che ha come inverso 1 stesso dato che 1.1=1. Il nostro insieme F si comporta formalmente come gli ordinari numeri
dell'aritmetica elementare. Le operazioni diventano, avendo solo due "numeri" coi quali operare, molto più semplici: ad esempio
esiste un solo "numero" diverso da x: questo è il "numero" x+1!
Fn = {(x1,x2,...,xn) : xi I vettori di questo spazio sono dunque le stringhe di zeri ed uno di lunghezza n. Poiché posso scegliere
x1 in due modi possibili, x2 in due modi possibili indipendenti da quelli, le stringhe di lunghezza due sono 2.2=4. In generale
le stringhe di lunghezza n sono 2n e dunque Fn è uno spazio vettoriale con un numero finito di vettori. In
generale se V è uno spazio vettoriale sul campo F di dimensione n allora ogni vettore di V si scrive in modo unico come
combinazione lineare di n vettori della base, ed essendo i coefficienti della combnazione lineare 0 o 1, vi sono 2n possibili
combinazioni lineari e dunque V ha 2n vettori.
In questo paragrafo presentiamo un metodo, dovuto a Hamming, per individuare
la presenza di un rumore che si produca durante la trasmissione di un segnale e, se il rumore è abbastanza piccolo, eliminarlo e, di
conseguenza, ricostruire esattamente il segnale trasmesso.
Questo metodo si serve di spazi vettoriali sul campo F con due elementi ed è di estrema importanza in molte applicazioni
della matematica all'informatica. Lo portiamo ad esempio per fornire allo studente una prima semplice applicazione di questi concetti. Il metodo che vogliamo esporre consiste nel codificare il modo diverso le parole di V in modo
che esse corrispondano agli elementi del nucleo di una opportuna matrice. Se durante la trasmissione queste nuove stringhe si modificano di poco
uscendo dal nucleo, riusciremo ugualmente riconoscerle e anche correggere l'errore. 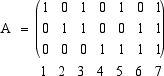 Notiamo che le colonne della matrice A rappresentano, nell'ordine, i numeri interi fino al 7 scritti in base due.
(1 si scrive 001, 2 si scrive 010, 3 si scrive 011, poi 100, 101 ecc) La matrice A è,
come si vede immediatamente, ridotta e il suo rango vale tre. Essa definisce quindi una applicazione lineare il cui nucleo ha dimensione 4. Calcoliamo ora esplicitamente, con i metodi che abbiamo visto in precedenza e applicabili qualunque sia il
campo degli scalari, una base per il Ker A. Possiamo scegliere come variabili libere la terza, la quinta la sesta e la settima. Risolvendo il sistema
Ax=0 a ritroso troviamo: Notiamo come i calcoli siano molto più semplici rispetto al caso in cui gli scalari sono numeri reali per il fatto che 1+1=0. Un vettore X del nucleo è quindi dato dalla combinazione lineare seguente: 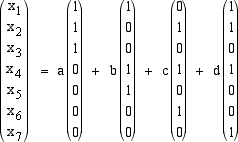 Indicando rispettivamente con u1 , u2 , u3 , u4 i 4 vettori
che abbiamo trovato, possiamo dire che ogni vettore x di Ker A si scrive in modo unico come loro combinazione lineare: Utilizziamo questa base per codificare le parole del nostro vocabolario in stringhe di lunghezza 7 elementi. Ciò viene fatto identificando
biunivocamente le parole con un vettore di Ker A: la parola
abcd sarà identificata al vettore au1 + bu2 + cu3 + du4, così,
ad esempio, la parola "giustizia" cioé 0101, sarà codificata col vettore u2 + u4 che risulta essere il
vettore (che quì scriviamo
per ragioni tipografiche come vettore riga) (0,1,0,0,1,0,1). Ora, per identificale il rumore e ricostruire il segnale originario, basta calcolare Aq'. Abbiamo infatti essendo ci la i-esima colonna della matrive A che rappresenta il numero i (cioé la componente che si è modificata) scritto in base 2. Se dunque p' è la parola che riveviamo, calcolando il prodotto Ap' troviamo tre numeri (y1,y2,y3) che mi dicono quale componete di p' devo cambiare per trovare il segnale originale p: la componente da cambiare è la componente
Supponiamo, ad esempio, che la parola da trasmettere sia "giustizia" cioè 0101, codificandola otteniamo il vettore di Ker A
u2 + u4 cioè il vettore (colonna) p=(0,1,0,0,1,0,1). Supponiamo ora che il vettore che riceviamo,
lievemente
disturbato, sia il vettore p' = (0,1,1,0,1,0,1). Calcolando Ap' troviamo (1,1,0) da cui i = 1+2 = 3, e quindi è la terza componente
di p' che va cambiata e il segmale originale, che non conoscevamo, è (0,1,0,0,1,0,1).
corrispondono alle parole che hanno la i-esima (e solo quella) componente modificata. |